
 成为VIP
成为VIP![体系课-慕课大数据工程师2023版完结[电子书+源码+视频]](https://quangneng.com/wp-content/uploads/2023/11/106852070c9cf592d33f2bebb653e6b.png)
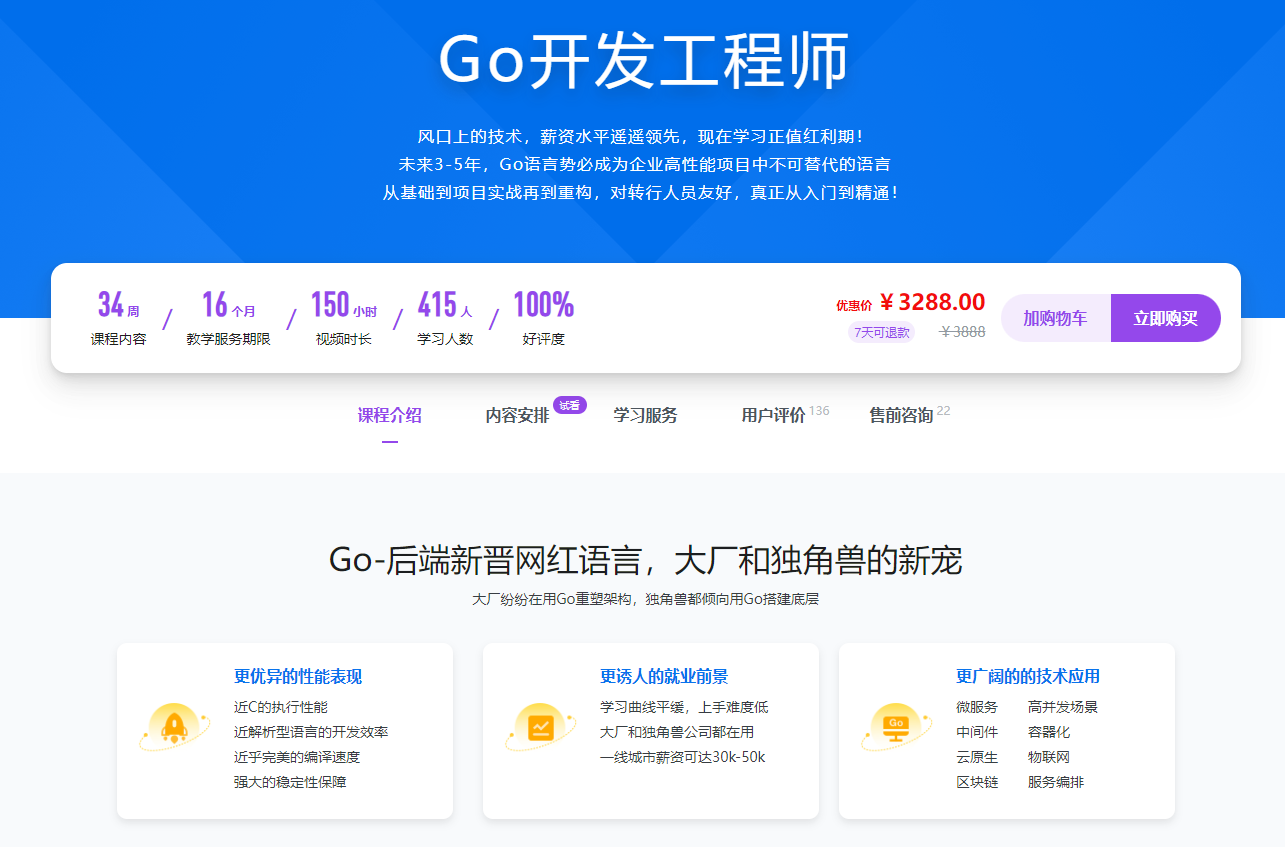
2023全新版-Go开发工程师
风口上的技术,薪资水平遥遥领先,现在学习正值红利期!
未来3-5年,Go语言势必成为企业高性能项目中不可替代的语言
从基础到项目实战再到重构,对转行人员友好,真正从入门到精通!
试看链接:https://pan.baidu.com/s/1CL8ngeiWbts9NpEIvake6w?pwd=4iuf
相关推荐:
JKSJ-初级go工程师训练营【完结】
【Go语言中文网】资深Go开发工程师第二期
Go开发工程师:迎接上升风口,踏入蓝海行业!【完结】
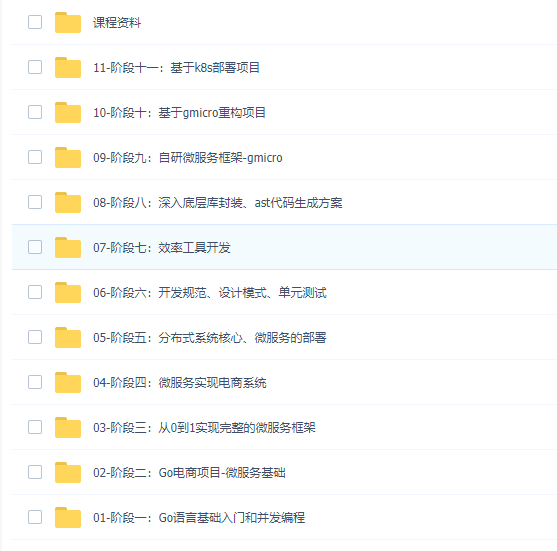
资源目录:
├──01-阶段一:Go语言基础入门和并发编程
| ├──第01周 Go基础知识入门
| | ├──第1章2022新版go工程师体系课导学以及Go的发展
| | ├──第2章go开发环境搭建
| | ├──第3章变量和常量
| | ├──第4章go的基础数据类型
| | ├──第5章字符串基本操作
| | └──第6章条件判断和for循环
| ├──第02周容器,go编程思想
| | ├──第1章数组、切片和map
| | ├──第2章函数
| | ├──第3章结构体
| | ├──第4章指针
| | └──第5章接口
| └──第03周Go并发编程和工程管理
| | ├──第1章package和gomodules
| | ├──第2章单元测试
| | └──第3章并发编程
├──02-阶段二:Go电商项目-微服务基础
| ├──第04周 从0开始理解rpc和grpc
| | ├──第1章开发环境搭建
| | ├──第2章rpc核心概念理解
| | ├──第3章go内置rpc快速开发
| | └──第4章grpc快速入门
| ├──第05周 grpc和protobuf进阶
| | └──第1章protobuf和grpc进阶
| ├──第06周 yapi文档管理、gorm详解
| | ├──第1章项目需求分析
| | ├──第2章单体应用到到微服务架构演进
| | ├──第3章yapi的安装和配置
| | └──第4章gorm快速入门
| └──第07周 gin快速入门
| | └──第1章gin快速入门
├──03-阶段三:从0到1实现完整的微服务框架
| ├──第08周 用户服务的grpc服务
| | └──第1章用户服务-service开发
| ├──第09周 用户服务的web服务
| | ├──第1章web层开发-基础项目架构
| | └──第2章web层开发-用户接口开发
| └──第10周 服务注册发现、配置中心、负载均衡
| | ├──第1章注册中心-consul
| | ├──第2章负载均衡
| | └──第3章分布式配置中心
├──04-阶段四:微服务实现电商系统
| ├──第11周 商品微服务的grpc服务
| | └──第1章商品服务-service服务
| ├──第12周 商品微服务的gin层和oss图片服务
| | ├──第1章gin完成商品服务的http接口
| | └──第2章阿里云的oss服务集成
| ├──第13周 库存服务和分布式锁
| | ├──第1章库存服务
| | └──第2章分布式锁
| ├──第14周 和购物车微服务
| | ├──第1章订单和购物车服务-service
| | └──第2章订单和购物车服务-web层
| ├──第15周 支付宝支付、用户操作微服务、前后端联调
| | ├──第1章支付宝支付
| | └──第2章收藏、收货地址、留言服务开发
| └──第16周 elasticsearch实现搜索微服务
| | ├──第1章elasticsearch常用接口
| | ├──第2章将elasticsearch集成到项目中
| | └──第3章前后端联调
├──05-阶段五:分布式系统核心、微服务的部署
| ├──第17周 分布式理论基础、分布式事务解决方案
| | ├──第1章电商系统中的库存归还、超时归还、事务等
| | └──第2章cap理论和分布式事务解决方案
| ├──第18周 学习rocketmq实现幂等性机制等
| | ├──第1章mq的应用场景和选型
| | ├──第2章rocketmq快速入门
| | ├──第3章基于可靠消息的最终一致性、订单超时归还
| | └──第4章实现接口的幂等性
| ├──第19周 链路追踪、限流、熔断、降级
| | ├──第1章链路追踪技术概述
| | ├──第2章go集成jaeger
| | └──第3章熔断、限流-sentinel
| └──第20周 api网关、部署
| | ├──第1章kong的安装和配置
| | ├──第2章kong的配置
| | ├──第3章jenkins入门
| | ├──第4章通过jenkins部署服务
| | └──第5章课程总结
├──06-阶段六:开发规范、设计模式、单元测试
| ├──第21周 开发规范和go基础扩展
| | ├──第1章开发规范
| | └──第2章go基础知识扩展
| └──第22周 设计模式和单元测试
| | ├──第1章设计模式
| | └──第2章单元测试
├──07-阶段七:效率工具开发
| └──第23周 protoc插件开发、cobra命令行
| | ├──第1章protoc自定义插件
| | └──第2章命令行开发神器-cobra
├──08-阶段八:深入底层库封装、ast代码生成方案
| ├──第24周 log日志包设计
| | └──第1章如何设计日志包
| └──第25周 ast代码生成工具开发
| | ├──第1章如何设计errors错误包
| | └──第2章通过ast自动生成代码
├──09-阶段九:自研微服务框架-gmicro
| ├──第26周 三层代码结构
| | └──第1章三层代码结构规范
| ├──第27周 grpc服务封装更方便的rpc服务
| | ├──第1章通用微服务框架需求
| | └──第2章开发通用的rpc服务
| ├──第28周 深入grpc的服务注册、负载均衡原理
| | └──第1章服务注册、服务发现和负载均衡
| ├──第29周 基于gin封装api服务
| | └──第1章基于gin封装通用的restserver
| ├──第30周 可观测的终极解决方案
| | └──第1章opentelemetry实现链路追踪
| └──第31周 系统监控核心
| | └──第1章监控系统-prometheus、grafana
├──10-阶段十:基于gmicro重构项目
| ├──第32周 用户、商品服务重构
| | ├──1-1 data层接口设计(1139).mp4 386.51M
| | ├──1-10 启动服务的bug修复(0311).mp4 121.15M
| | ├──1-11 用户服务的api层服务初始化(1008).mp4 286.70M
| | ├──1-12 重构login接口(1445).mp4 560.17M
| | ├──1-13 用户服务的data层重构(2103).mp4 694.17M
| | ├──1-14 重构login的service等代码(1532).mp4 538.59M
| | ├──1-15 完成login的controller层重构(2009).mp4 997.92M
| | ├──1-16 封装底层的rpc链接(1628).mp4 548.81M
| | ├──1-17 封装rpc服务的client端tracing拦截器(1223).mp4 610.12M
| | ├──1-18 重构短信发送逻辑(1720).mp4 552.48M
| | ├──1-19 基于redis的封装(2447).mp4 1.21G
| | ├──1-2 userstore接口的实现(2305).mp4 776.06M
| | ├──1-20 重构注册接口(1945).mp4 682.85M
| | ├──1-21 登录校验(2056).mp4 899.91M
| | ├──1-22 调试token解析(1522).mp4 724.21M
| | ├──1-23 更新用户信息接口重构(0535).mp4 209.33M
| | ├──1-3 重构service层接口实现(0645).mp4 226.53M
| | ├──1-4 重构controller层代码-list和通过id查询用户(0915).mp4 381.94M
| | ├──1-5 重构controller层代码-通过mobile查询用户(1245).mp4 429.55M
| | ├──1-6 重构controller层代码-用户更新和密码校验(1049).mp4 388.81M
| | ├──1-7 底层数据库的链接封装(1606).mp4 615.12M
| | ├──1-8 mysql的配置和映射启动服务(1612).mp4 596.55M
| | ├──1-9 mysql配置文件映射启动(1045).mp4 418.13M
| | ├──2-1 定义商品服务的DO模型(1851).mp4 652.47M
| | ├──2-10 通过map-reduce完成并发调用控制(1641).mp4 679.58M
| | ├──2-11 启动goods的service服务(2903).mp4 1.02G
| | ├──2-12 通过工厂模式改造service和data层(3012).mp4 1.29G
| | ├──2-13 启动商品服务(0923).mp4 363.59M
| | ├──2-14 完成controller层的商品列表接口(0545).mp4 294.62M
| | ├──2-15 调试商品列表页接口(1602).mp4 667.95M
| | ├──2-16 gorm打印日志的集成(0851).mp4 415.51M
| | ├──2-17 商品服务的api接口重构-1(2236).mp4 979.41M
| | ├──2-18 商品服务的api接口重构-2(1418).mp4 730.95M
| | ├──2-2 重构商品相关的接口(1217).mp4 654.44M
| | ├──2-3 重构商品服务其他接口的data接口(1123).mp4 486.74M
| | ├──2-4 商品列表页重构需求分析(1057).mp4 371.54M
| | ├──2-5 重构商品服务的es接口(1633).mp4 551.23M
| | ├──2-6 重构商品服务的es查询接口(1058).mp4 371.05M
| | ├──2-7 重构service层商品列表页接口(1443).mp4 636.17M
| | ├──2-8 基于事务完成商品的创建(2218).mp4 1.10G
| | └──2-9 通过canal消费mysql的binlog完成数据最终一致性的方案(1022).mp4 238.51M
| ├──第33+周 订单服务重构、wire进行ioc控制
| | ├──1-1 订单系统data层数据接口定义(1543).mp4 506.16M
| | ├──1-10 调试新建订单接口(下)(2033).mp4 1.10G
| | ├──1-2 实现order和购物车的接口重构(2906).mp4 1.09G
| | ├──1-3 完成datafactory的重构(1509).mp4 590.03M
| | ├──1-4 订单服务的service层重构(1045).mp4 315.88M
| | ├──1-5 通过saga事务重构分布式事务(2306).mp4 1.14G
| | ├──1-6 新建订单和补偿接口实现(1753).mp4 625.70M
| | ├──1-7 重构controller层的submitorder接口(2628).mp4 1.36G
| | ├──1-8 启动订单服务重构(1732).mp4 940.38M
| | ├──1-9 调试新建订单接口(上)(2250).mp4 1.17G
| | ├──2-1 什么是ioc(3003).mp4 893.19M
| | ├──2-2 ioc框架选型(1109).mp4 219.12M
| | ├──2-3 wire快速入门(1325).mp4 336.88M
| | ├──2-4 通过wire重构user的service服务(上)(2236).mp4 877.54M
| | ├──2-5 通过wire重构user的service服务(下)(1853).mp4 767.08M
| | ├──2-6 通过providerset简化初始化(0833).mp4 310.10M
| | ├──2-7 sentinel集成nacos(3103).mp4 913.28M
| | ├──2-8 集成sentinel和nacos(2349).mp4 1.06G
| | └──2-9 调试sentinel集成nacos(1323).mp4 507.70M
| └──第33周 订单、库存等服务重构
| | ├──1-1 api服务的service层重构(3007).mp4 1.11G
| | ├──1-2 重构库存服务的data层接口实现(1723).mp4 723.68M
| | ├──1-3 service层重构get和create方法(0750).mp4 235.84M
| | ├──1-4 库存扣减接口重构(2416).mp4 1.00G
| | ├──1-5 重构reback库存归还接口(1657).mp4 597.33M
| | ├──2-1 saga分布式事务的原理(2258).mp4 597.33M
| | ├──2-2 各种分布式事务的应用场景(0544).mp4 734.78M
| | ├──2-3 dtm的安装(1027).mp4 348.08M
| | ├──2-4 dtm快速体验saga分布式事务(2509).mp4 827.78M
| | ├──2-5 转账服务的saga事务调试(1756).mp4 782.48M
| | ├──2-6 grpc服务的事务编排(2631).mp4 1.42G
| | ├──2-7 基于服务发现完成分布式事务的调度(1338).mp4 701.14M
| | └──2-8 子事务屏障和gin集成测试(2549).mp4 1.34G
├──11-阶段十一:基于k8s部署项目
| ├──第34+周 devops和k8s
| | ├──1-1 基于docker进行go build构建(1408).mp4 261.37M
| | ├──1-10 jenkins构建后发布到k8s中(2333).mp4 511.48M
| | ├──1-11 对user服务进行ci构建(1450).mp4 380.07M
| | ├──1-12 kubesphere部署用户服务(2330).mp4 529.31M
| | ├──1-13 修改user服务的配置(1953).mp4 598.71M
| | ├──1-14 解决gmicro的ip地址的bug(1122).mp4 351.22M
| | ├──1-15 测试用户服务(0634).mp4 229.55M
| | ├──1-16 k8s的service的负载均衡和本地负载均衡的区别(1816).mp4 650.64M
| | ├──1-17 部署admin的api服务(1139).mp4 327.02M
| | ├──1-18 通过ingress暴露service(1421).mp4 236.56M
| | ├──1-2 通过多阶段构建对go镜像瘦身(1416).mp4 304.51M
| | ├──1-3 完善多阶段构建的dockerfile(0600).mp4 146.63M
| | ├──1-4 devops、ci、cd和gitops等概念(2137) .mp4 699.21M
| | ├──1-5 安装git parameter插件(1220).mp4 303.60M
| | ├──1-6 如何构建一个生产环境的镜像?(0632).mp4 91.70M
| | ├──1-7 pipeline参数化构建(1945).mp4 292.71M
| | ├──1-8 编写Dockerfile(0933).mp4 216.66M
| | ├──1-9 编写jenkinsfile完成docker构建和发布(1443).mp4 444.17M
| | ├──2-1 k8s学习路线(0855).mp4 259.72M
| | ├──2-10 课程总结和进一步学习建议(2112).mp4 278.28M
| | ├──2-2 pod是什么?(0923).mp4 217.89M
| | ├──2-3 kubectl相关的pods命令(1653).mp4 556.58M
| | ├──2-4 k8s的控制器 – deployment(1853).mp4 491.30M
| | ├──2-5 k8s的service(1846).mp4 588.06M
| | ├──2-6 k8s的ingress(1049).mp4 316.66M
| | ├──2-7 k8s的持久卷(1212).mp4 376.97M
| | ├──2-8 k8s的configmap、secret(0809).mp4 302.19M
| | └──2-9 k8s的架构(1340).mp4 421.93M
| └──第34周 通过k8s部署服务
| | ├──1-1 基于docker进行go build构建(1408).mp4 260.98M
| | ├──1-10 jenkins构建后发布到k8s中(2333).mp4 505.76M
| | ├──1-11 对user服务进行ci构建(1450).mp4 418.93M
| | ├──1-12 kubesphere部署用户服务(2330).mp4 527.66M
| | ├──1-13 修改user服务的配置(1953).mp4 597.68M
| | ├──1-14 解决gmicro的ip地址的bug(1122).mp4 352.75M
| | ├──1-15 测试用户服务(0634).mp4 228.49M
| | ├──1-16 k8s的service的负载均衡和本地负载均衡的区别(1816).mp4 646.10M
| | ├──1-17 部署admin的api服务(1139).mp4 321.60M
| | ├──1-18 通过ingress暴露service(1421).mp4 234.57M
| | ├──1-2 通过多阶段构建对go镜像瘦身(1416).mp4 304.85M
| | ├──1-3 完善多阶段构建的dockerfile(0600).mp4 146.74M
| | ├──1-4 devops、ci、cd和gitops等概念(2137) .mp4 693.05M
| | ├──1-5 安装git parameter插件(1220).mp4 302.76M
| | ├──1-6 如何构建一个生产环境的镜像?(0632).mp4 89.86M
| | ├──1-7 pipeline参数化构建(1945).mp4 288.17M
| | ├──1-8 编写Dockerfile(0933).mp4 245.29M
| | ├──1-9 编写jenkinsfile完成docker构建和发布(1443).mp4 443.43M
| | ├──2-1 k8s学习路线(0855).mp4 256.77M
| | ├──2-10 课程总结和进一步学习建议(2112).mp4 274.65M
| | ├──2-2 pod是什么?(0923).mp4 217.67M
| | ├──2-3 kubectl相关的pods命令(1653).mp4 553.53M
| | ├──2-4 k8s的控制器 – deployment(1853).mp4 487.22M
| | ├──2-5 k8s的service(1846).mp4 584.50M
| | ├──2-6 k8s的ingress(1049).mp4 315.14M
| | ├──2-7 k8s的持久卷(1212).mp4 375.61M
| | ├──2-8 k8s的configmap、secret(0809).mp4 293.33M
| | └──2-9 k8s的架构(1340).mp4 419.03M
└──课程资料
| ├──课程资料
| | ├──Go工程师体系课全新版电子教程
| | └──mxshop
| ├──mxshop-api.rar 15.35M
| └──mxshop.rar 6.33M



